
原来,这些顶级大模型都是蒸馏的
原来,这些顶级大模型都是蒸馏的「除了 Claude、豆包和 Gemini 之外,知名的闭源和开源 LLM 通常表现出很高的蒸馏度。」这是中国科学院深圳先进技术研究院、北大、零一万物等机构的研究者在一篇新论文中得出的结论。
来自主题: AI技术研报
10035 点击 2025-01-29 13:26
 搜索
搜索
「除了 Claude、豆包和 Gemini 之外,知名的闭源和开源 LLM 通常表现出很高的蒸馏度。」这是中国科学院深圳先进技术研究院、北大、零一万物等机构的研究者在一篇新论文中得出的结论。

对 LLM 来说,Pre-training 的时代已经基本结束了。视频模型的 Scaling Law,瓶颈还很早。具身智能:完全具备人类泛化能力的机器人,在我们这代可能无法实现
Grok AI 最近网页版刚刚上线。我看到不少人都在比较 Grok 对标 ChatGPT 等等 LLM 大模型的研究和生成能力。我想说,背靠 X (前推特)数据库的 Grok AI,最好的使用方式难道不是实时监测全球媒体热点吗?
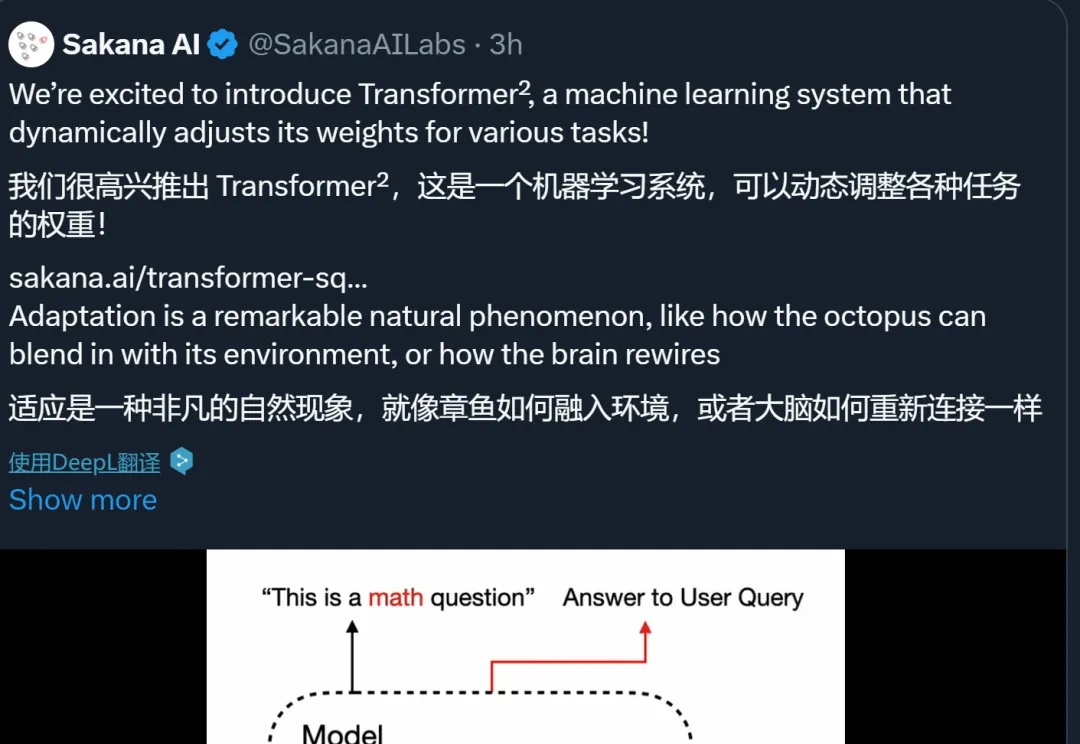
自适应 LLM 反映了神经科学和计算生物学中一个公认的原理,即大脑根据当前任务激活特定区域,并动态重组其功能网络以响应不断变化的任务需求。
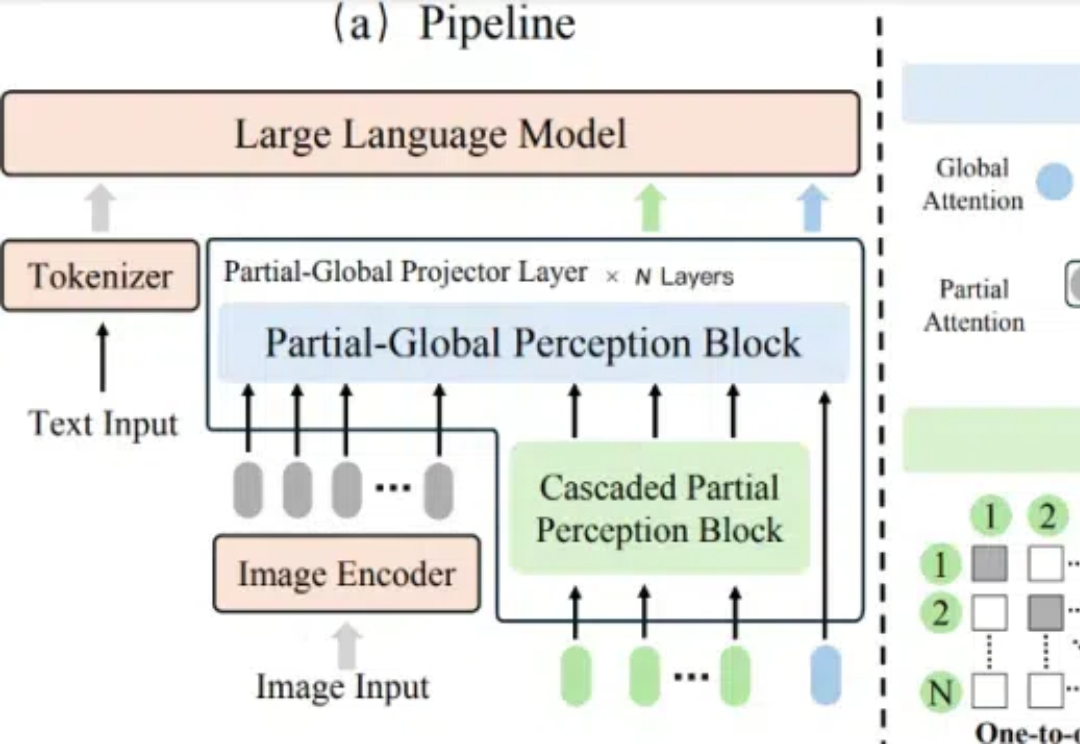
在多模态大语言模型(MLLMs)的发展中,视觉 - 语言连接器作为将视觉特征映射到 LLM 语言空间的关键组件,起到了桥梁作用。
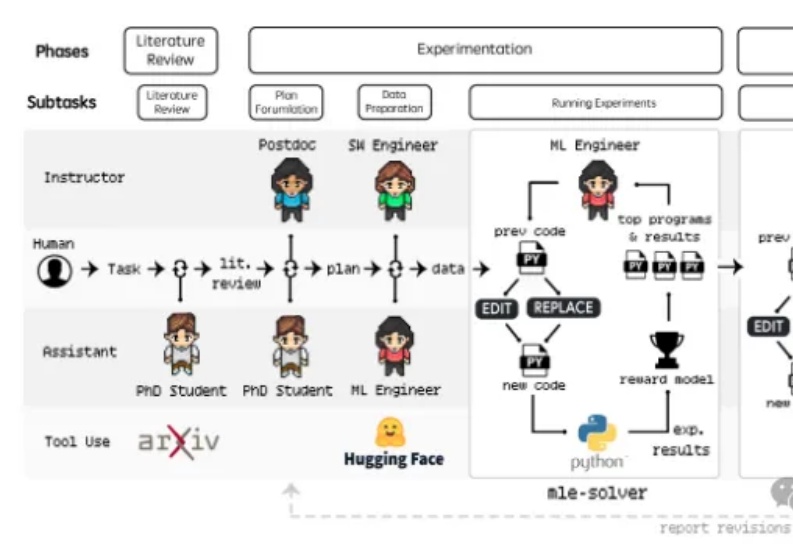
发表于昨天的论文《Agent Laboratory: Using LLM Agents as Research Assistants》对于科研界具有划时代意义,过去几周才能完成的科研任务现在仅需20分钟到一两个小时左右(不同LLM),花费2-13个美金的Token即可完成!
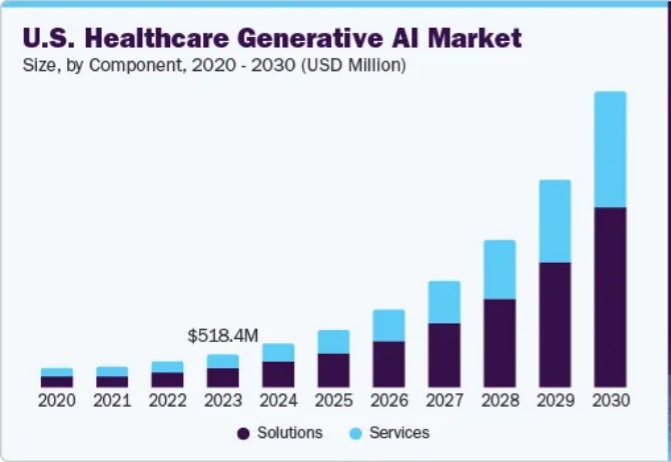
在 LLM 落地场景中,医疗领域的应用开始展现出比较高的确定性,尤其是 AI scribe 产品能解决临床文档记录枯燥、耗时这一行业痛点。Abridge 是其中最有代表性的公司,训练了专用于临床文档的 ASR 和文本生成模型,能够替代 90% 左右的人工工作量。
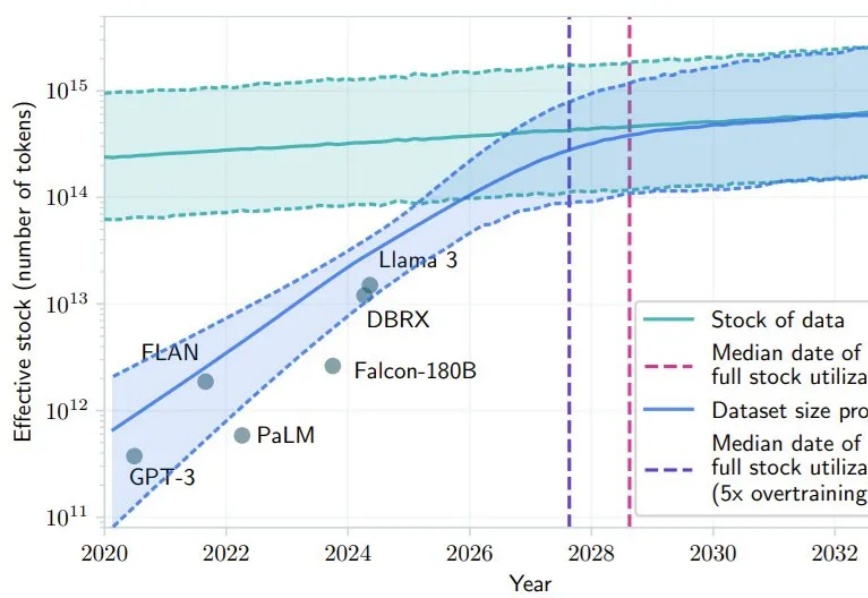
最近 AI 社区很多人都在讨论 Scaling Law 是否撞墙的问题。其中,一个支持 Scaling Law 撞墙论的理由是 AI 几乎已经快要耗尽已有的高质量数据,比如有一项研究就预计,如果 LLM 保持现在的发展势头,到 2028 年左右,已有的数据储量将被全部利用完。
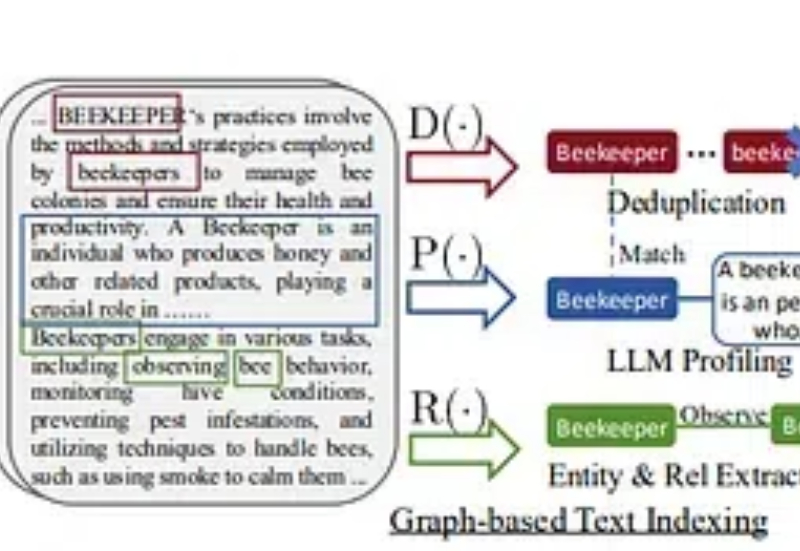
在这个故事中,我将提供一个快速教程,展示如何使用浏览器使用、LightRAG和本地LLM创建一个强大的聊天机器人,以开发一个能够抓取您选择的任何网站的AI代理。此外,您可以询问有关您的数据的问题,这将为您提供该问题的回答。

本月,OpenAI科学家就当前LLM的scaling方法论能否实现AGI话题展开深入辩论,认为将来AI至少与人类平分秋色;LLM scaling目前的问题可以通过后训练、强化学习、合成数据、智能体协作等方法得到解决;按现在的趋势估计,明年LLM就能赢得IMO金牌。